Blogged: VM High Availability in @Azure Resource Manager needs more than Availability Sets http://blog.geuer-pollmann.de/blog/2015/09/15/vm-ha-in-arm-needs-more-than-availabilitysets//
— Chris Geuer-Pollmann (@chgeuer) 16. September 2015tl’dr
- You use Azure Resource Manager.
- For fault tolerance, you deploy multiple virtual machines, such as a the frontend nodes, into an availability set. You use the
copyIndex()function for looping through the cluster - From a fault tolerance and performance perspective, putting all frontend VM VHD files into a single storage account is a bad idea.
- This article describes how you can declaratively distribute the OS disks across multiple storage accounts.

Intro
Azure Resource Manager is Microsoft Azure’s new declarative mechanism for deploying resources, so instead of writing a complex imperative script and firing a large amount of management operations against the Azure Service Management REST API, you describe the overall deployment in a JSON file,
The file LinuxVirtualMachine.json contains an ARM template which deploys the following resources:
- A virtual network to put all VMs in
- An availability set for all VMs
- 7 virtual machines and their associated network interface cards, and
- 2 storage accounts for the OS disks of the virtual machines.
An ‘availability set’ is a mechanism to force Azure to distribute the VMs which belong to the availability set across multiple “fault domains” and “upgrade domains”. Each of the 3 fault domains has own power supplies, networking gear, etc., so that a power outage for instance only impacts all VMs in that one fault domain.
Sharding across storage accounts
To function properly, each “virtual machine” needs to have an “OS disk”, which is stored in a “storage account”. Azure storage accounts have an availability SLA of 99.9% for locally redundant storage (LRS). Virtual machines running in an availability set have an SLA of 99.95%. It becomes clear that having highly available virtual machines, but then putting all eggs into one basket, eh, all OS disks into the same storage account, is a bad idea.
In addition to the availability issue of a single storage account, we also should distribute OS and data disks for performance reasons. When you read the Azure Storage Scalability and Performance Targets, you see the recommendation that you should put a maximum of 40 ‘highly utilized’ VHD disks into a regular (non-premium) storage account. So sharding helps both with HA and load leveling.
The solution
In that JSON template file, the three parameters are adminUsername, adminPassword are self-explanatory. The deploymentName parameter will be used as prefix for all sorts of naming, such as being a prefix for the (globally unique) storage account name.
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"adminUsername": { "type": "string", ... },
"adminPassword": { "type": "securestring", ... },
"deploymentName": { "type": "string", ...}
},
...
}
The variables section contains values derived from the deploymentName parameter, and some constants, such as the instance count for the frontend nodes (the VMs). Noteworthy here is the math.modulo2 helper array, which we’ll see in action later.
{
...,
"variables": {
"vnetname": "[concat(parameters('deploymentName'),'-vnet')]",
"storageAccountNamePrefix": "[toLower(replace(parameters('deploymentName'),'-',''))]",
"storageAccountNames": {
"frontend": "[concat(variables('storageAccountNamePrefix'), 'fe')]"
},
"instanceCount": {
"frontend": 7
},
"math": {
"modulo2": [ "0", "1", "0", "1", "0", "1", "0", "1", "0", "1", ... ]
}
}
}
One tip for deriving storage account names from user-supplied strings is to do at least some input sanitization. Above, you see that I call the `replace(deploymentName,'-','')` function to trim away dashes. Azure storage accounts do not like dashes and symbols in their name. Until ARM templates provide some RegEx'ish input handling, I at least trim the `-` symbols away.
The interesting part of the JSON template is in the virtual machine description. The copy.count value retrieves the instance count from the variablessection: [variables('instanceCount').frontend], which means that the template is expanded 7 times. The concrete value of the iteration is returned by the copyIndex() function, which returns 0, 1, 2, 3, 4, 5 and 6 respectively.
The properties.storageProfile.osDisk.vhd.uri has a value, which needs some explanation, indented for better redability:
[concat(
'http://',
variables('storageAccountNames').frontend,
variables('math').modulo2[copyIndex()], <-- Here we use copyIndex() as
'.blob.core.windows.net/vhds/fe-', indexer into our math helper
copyIndex(),
'-osdisk.vhd'
)]"
Consider the following values:
deploymentName = "test123"
variables('storageAccountNames').frontend == "test123fe"
variables('instanceCount').frontend = 7
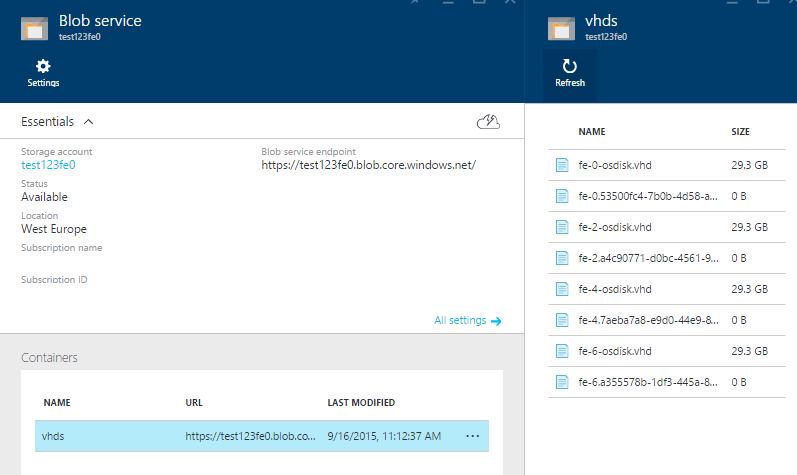
All disks of VMs with an even number end up in storage account test123fe0, all odd OS disks end up in test123fe1. The URLS of the resulting seven OS disks are shown here:
https://test123fe0.blob.core.windows.net/vhds/fe-0-osdisk.vhd
https://test123fe0.blob.core.windows.net/vhds/fe-2-osdisk.vhd
https://test123fe0.blob.core.windows.net/vhds/fe-4-osdisk.vhd
https://test123fe0.blob.core.windows.net/vhds/fe-6-osdisk.vhd
https://test123fe1.blob.core.windows.net/vhds/fe-1-osdisk.vhd
https://test123fe1.blob.core.windows.net/vhds/fe-3-osdisk.vhd
https://test123fe1.blob.core.windows.net/vhds/fe-5-osdisk.vhd
The virtual machine description looks like this:
{
"resources": [
{
"type": "Microsoft.Compute/virtualMachines",
"name": "[concat('fe', '-', copyIndex())]",
"copy": {
"name": "frontendNodeVMCopy",
"count": "[variables('instanceCount').frontend]"
},
"dependsOn": [
"[concat('Microsoft.Storage/storageAccounts/', concat(variables('storageAccountNames').frontend, variables('math').modulo2[copyIndex()]))]",
],
"properties": {
"hardwareProfile": { "vmSize": "Standard_A0" },
"networkProfile": ...,
"availabilitySet": ...,
"osProfile": {
"computerName": "[concat('fe-', copyIndex())]",
...
},
"storageProfile": {
"imageReference": ...,
"osDisk": {
"name": "[concat('fe-', copyIndex(), '-osdisk')]",
"vhd": {
"uri": "[concat('http://',
variables('storageAccountNames').frontend,
variables('math').modulo2[copyIndex()],
'.blob.core.windows.net/vhds/fe-',
copyIndex(),
'-osdisk.vhd') ]"
},
"caching": "ReadWrite", "createOption": "FromImage"
}
}
}
},
...
]
}
What doesn’t work
Azure Resource Manager contains a bunch of functions, such as the concat() function for concatenating strings.
Since August 2015, it also contains a mod()function for computing the modulus, but I haven’t been able to get that to work. I tried various combinations, such as
mod(copyIndex(), 2)string(mod(int(copyIndex()), 2))mod(copyIndex(), variables('storageAccountShardingCount'))string(mod(int(copyIndex()), variables('storageAccountShardingCount')))
but none of those worked. Therefore, I decided to stick with my own approach for the time being
- Having the math helper
"variables": { "math": { "modulo2": [ "0", "1", "0", "1", "0", "1", "0", "1", "0", "1", ... ] } } - and then using that array to ‘compute’ the %2:
[variables('math').modulo2[copyIndex()]]
Nevertheless, my preferred approach would be to have a storageAccountShardingCount variable which contains the number of storage accounts to spread the load over, and then use mod(copyIndex(), variables('storageAccountShardingCount')) to compute the respective storage account, like in this sample. Unfortunately, this currently gives me
Error submitting the deployment request.
Additional details from the underlying API that might be helpful:
Deployment template validation failed:
The template resource '...' at line '..' and column '..' is not valid.
Template language expression "mod(copyIndex(), variables('storageAccountShardingCount'))"" is not supported..'
Demo time
If you want have a look yourself, check the LinuxVirtualMachine.json file, which contains an ARM template, or deploy it into your Azure subscription by clicking below button. It will prompt you for an admin username and password, and a prefix string for naming the resources, and than launch 7 Standard_A0 instances (extra small, just for the sake of the argument):

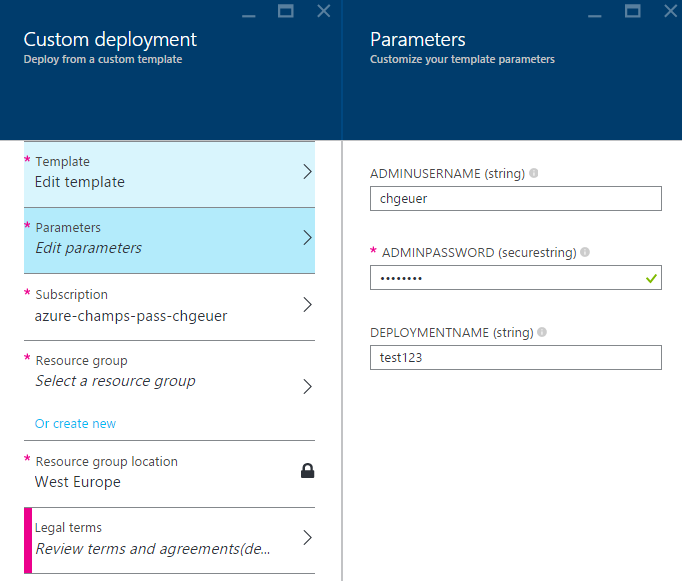
After clicking the button, you’re signed into the Azure portal, and you can provide your own parameter values:
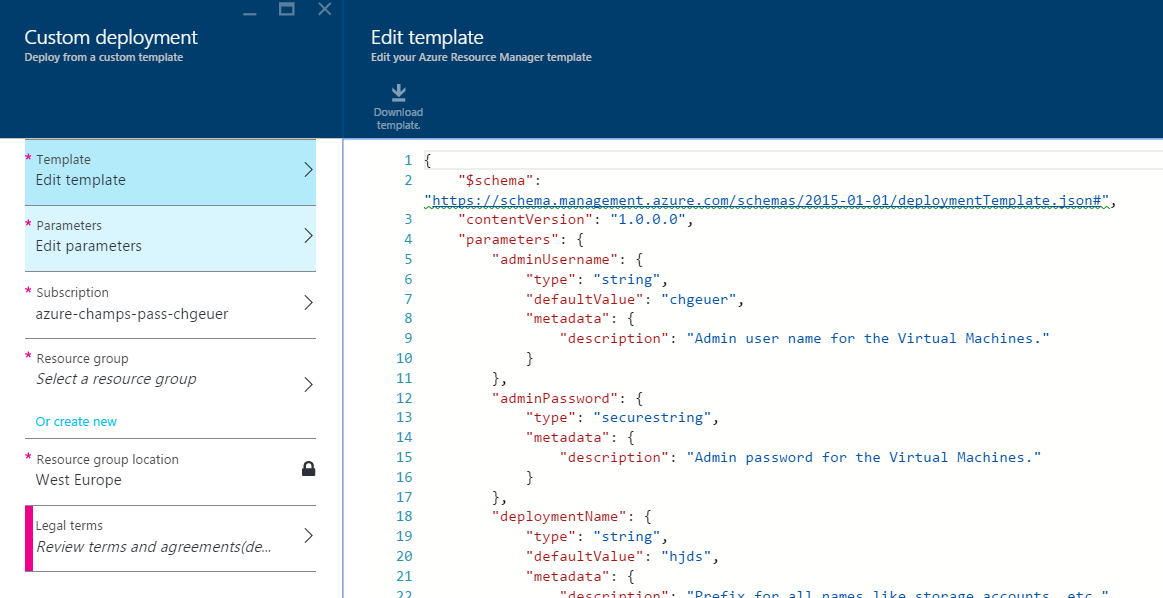
If you choose so, you can review my template and make modifications:
Choose some new resource group, as you’ll want to delete all the demo content later in a single shot.
For some reasons, you need to acknowledge the “buy” operation
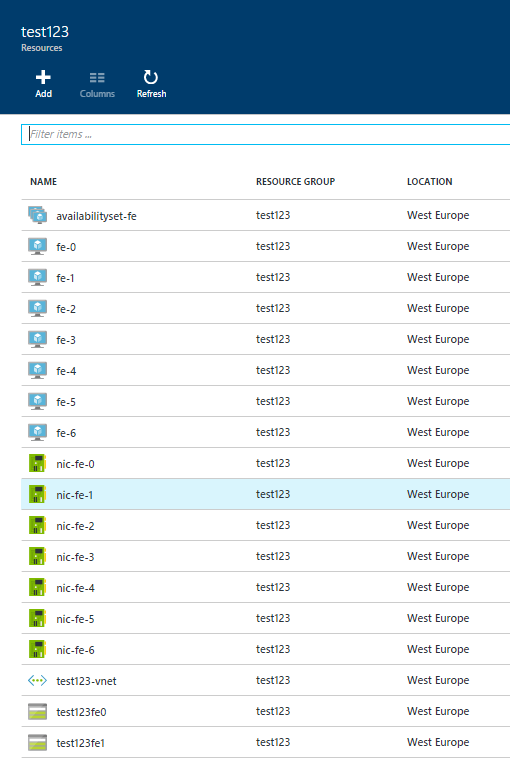
After resource creation, you can drill into your resource group, and see the 7 VMs, two storage accounts, and all the other things:
When you drill into one storage account, the blob service, and the vhds container, you can see the OS disks.